



CrewAI: Extracting PDFs, What Worked?
- Why Docling
- Embedding: What is happening?
- CrewAI: Setting up and retrieving knowledge
- Local LLM and Pydantic validation
- Conclusions
- References
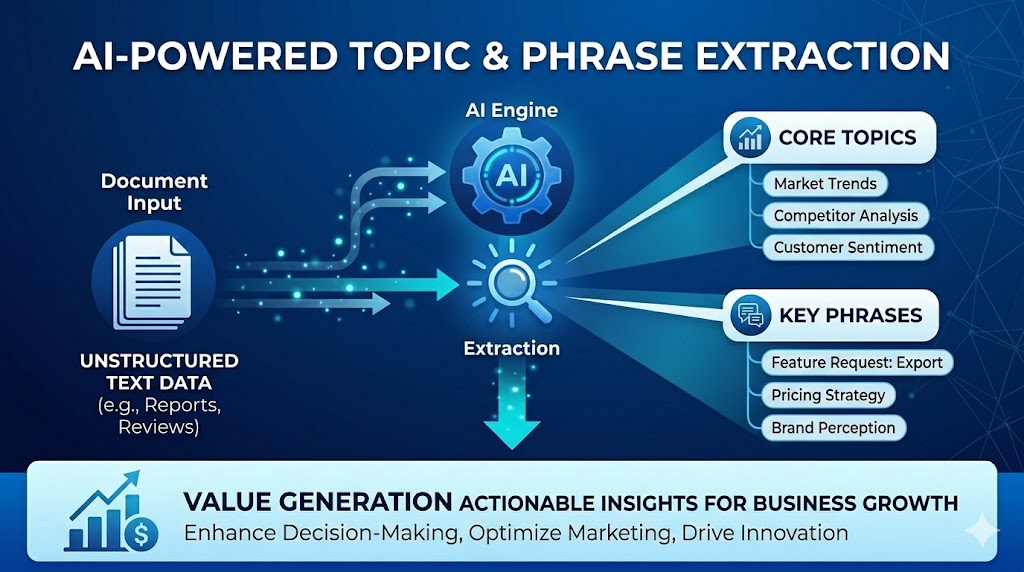
This is a great example of “making AI work for you”. It replaced a manual extraction step and built a framework that is reusable across different problem spaces. In this article, we discuss getting the most out of CrewAI and RAG search/retrieval.
Using CrewAI [1] on a recent project, we discovered a few settings that significantly helped improve accuracy when building local data extraction. We thought they were well worth sharing. The task was simple: extract structured data from historic PDF reports, but the data could not leave the site.

