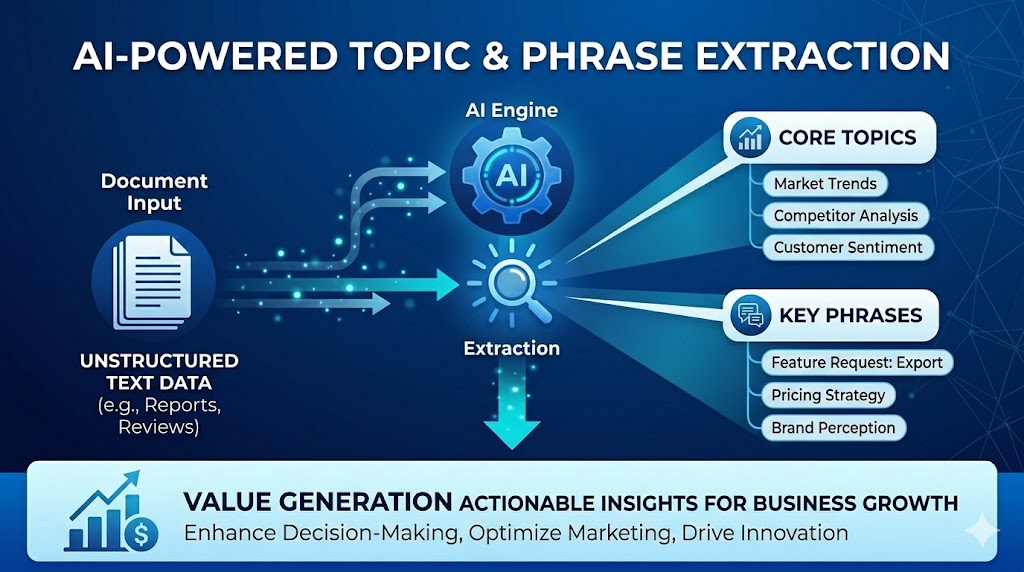
Learning Phrases with PyLucene and Pytorch, part 2.
In part 2 we reuse our tokenised index and use pytorch to build a model for significant phrase extraction. It worked surprisingly well and being able to switch Analyzers proved useful. We found that the English Analyzer with stopword removal and stemming worked best.
The results are indicative, neither the dataset size or the length of training cycles are sufficient for the development of a genralised phrase extractor but the succcess and ovelap found between pylucene and pytorch is very encouraging. We just need to scale it up.
